Test-driven development has become quite a buzzword these days, with some companies produly announcing that they pursue it, some brushing it off as the latest coding fad, and some falling somewhere in between: writing and running some tests, but well after the code was actually written.
What does it Do?
Technically, it means writing both code and automated tests for it simultaneously.
I like TDD for two main reasons:
It forces you to think about your code and your product and be proactive about what could break.
It does tell you when something breaks – why would you not want to pursue that?
It helps you future-proof your code, especially if someone other than you might be using it. Seeing tests written for an app is a great way to understand how that app works.
Rails comes with some skeleton tests that are designed when creating a new project or running a scaffold (run -T or --skip-test-unit to avoid having tests be created with rails new; run --no-test-framework when using a generator.) They are usually found in your test folder.
Interestingly, DHH, the man who created Rails, does not practice TDD at all and advocates in favor of live testing.
While there are some good books on test-driven development on Amazon, there are a lot fewer of them than
I have been thinking of good ways to frame test-driven development.
Here are some things I have learned so far:
Write Tests First
I think the tricky thing is to actually pursue test-driven development – as in, to let the tests drive your code, and not write tests after you finish coding. I am most certainly guilty of the latter. Pursuing the latter is actually still better than not writing any tests, but to me, having the tests drive what you are building implies a much better understanding of your code.
So that’s the idea: write a test, write enough code for the test, repeat.
Red-Green-Refactor
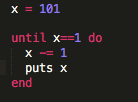
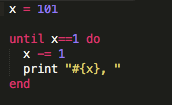
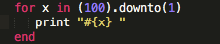
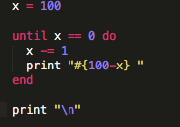
There are multiple approaches to writing tests. Red-green refactoring is what I really like: make the test fail (show up as red in your Terminal depending on the language you are running) before you make it turn green / pass. That way, you are actually ensuring you understand what your test is doing by breaking it and assembling it back together. Then refactor your code if it can use optimization, and repeat.
When writing tests that fail first is that the test is just an ideation of what your code is suppsoed to do, but the code is not there / ready yet, and your job is to make it pass.
Where Do I start?
I have found it helpful to start with accessing what the code has to accomplish. Outside of the generic ‘this app has to serve as a social network for ferrets’ mission, it helps to go through the basic ideas:
- What are specific things my code / app needs to go?
- How should be able to manipulate my code / app?
- What are inputs and outputs that go into the code?
- What are the errors and some edge cases? (I always find I think of more edge cases and go back to add tests for them as I keep working on a project.)
- With regard to errors, it is helpful to know some basic Ruby errors / exceptions so that you can speicficialyl test for them. Read more on exception handling here.
Which brings me to:
How Do I run Tests?
RSpec is one of the most popular Ruby gems.
Run rspec install, bundle and then rspec --init.
There are a lot more laws, principles, and tips on how to actually use rspec out there, and I plan to talk more about it in the future.
Extra Credit
If you are looking for more detailed TDD steps, some good input can be found here.